
汇编学习笔记
目录(书中目录和我的添加,添加带有*)
- 使用书籍和学习目的 *
- Ubuntu下的汇编环境 *
- Debug的简易教程 *
- 必要的基础知识 *
- 寄存器
- 内存访问
- 编译第一个汇编程序
- [BX]和loop指令
- 含有多个段的开发方法
- 更灵活的定位内存方式
- 数据处理的基本问题
- 转移指令的原理
- CALL和RET指令
- 标志寄存器
- 内中断
- INT指令
- 外中断
- 直接定址表
- 利用BIOS读取键盘输入和对磁盘读写
- 附录
使用书籍和学习目的
使用的主要书籍:为王爽老师所著的《汇编语言 第三版》。只有这一本书籍,关于书籍习题答案,可以上网搜索,网上有人已经进行了这章节后的习题回答及其简单解释。
有时候会插入其他一些书籍的小说明。
次要书籍:
学习目的:我学习汇编语言的目的是为了了解CPU和主板上的其他设备是如何相互作用的,以及为了学习操作系统的仿写做准备。
注意:汇编语言的语法并不难,难点在于基本原理,代码甚至可以不会,但是基本原理必须得懂。
Ubuntu下的汇编环境
下载所需工具
!以下操作皆在shell中!
在Ubuntu下安装
DOSBOX:sudo apt install dosbox安装git工具,用来下载
3:sudo apt install git下载所需工具:
git clone https://gitee.com/xeanyu/dosboxtools进入环境:
dosbox装载工具(在dosbox中):
mount c: ~/dosboxtools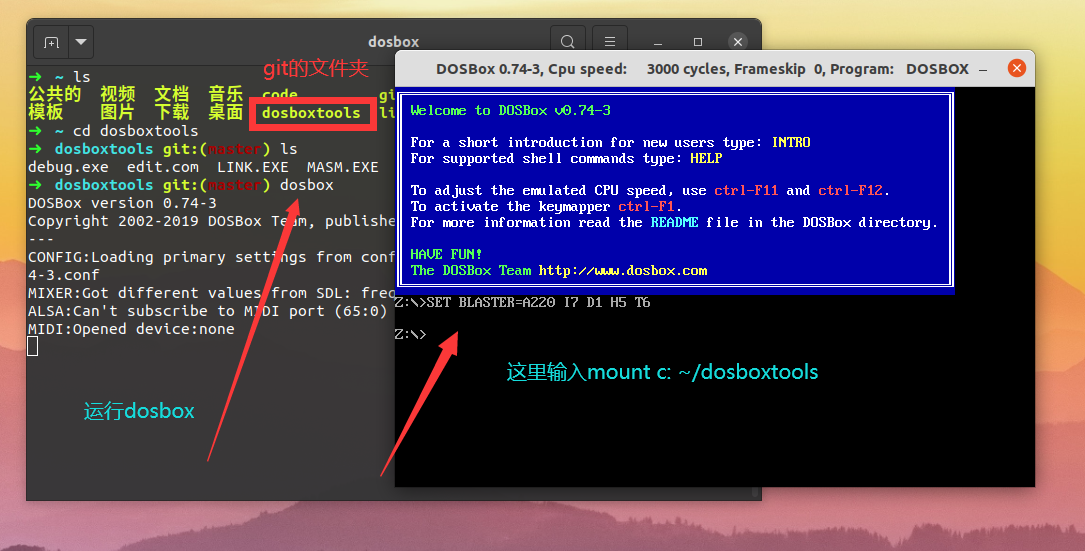
在dosbox中输入:
c:即可在dosbox中进入文件夹dosboxtools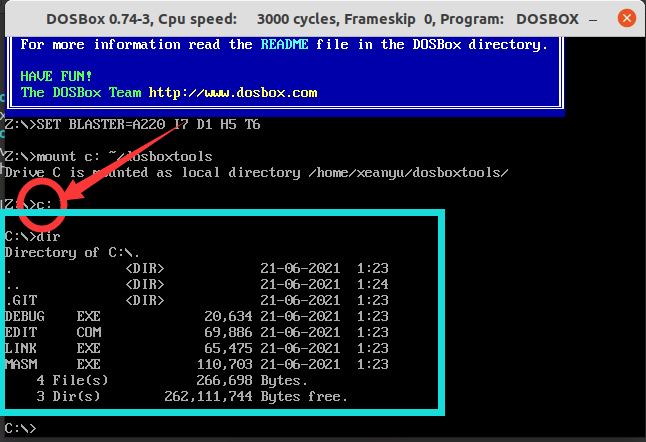
输入
debug进入汇编调试工具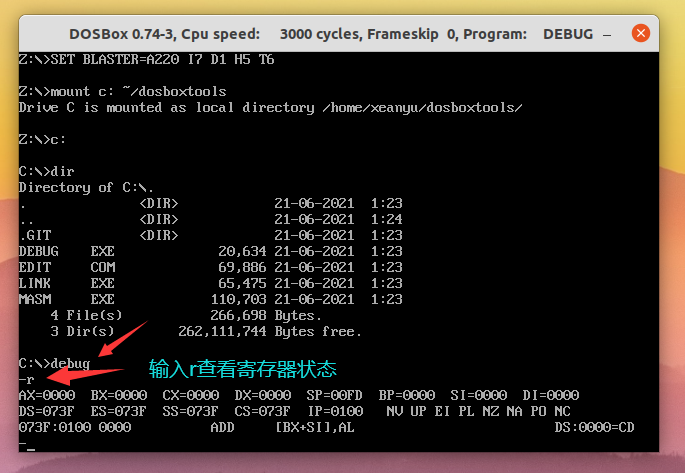
Debug简易教程
进入debug环境后,我们可以通常以下指令对寄存器,内存进行操作。
r命令,可以进行查看,修改CPU寄存器的内容;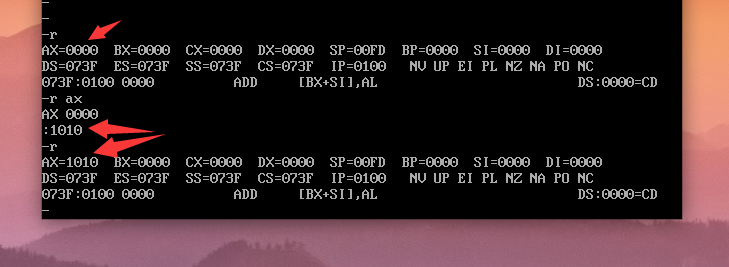
d 段地址(SA):偏移地址(EA)命令,可以查看对应地址的内存单元的数据;
e 段地址(SA):偏移地址(EA) 内容1 内容2 ...命令,可以修改对应地址内存单元中的数据;
u 段地址(SA):偏移地址(EA)命令,可以查看对应地址的内存单元中的内容翻译成汇编指令;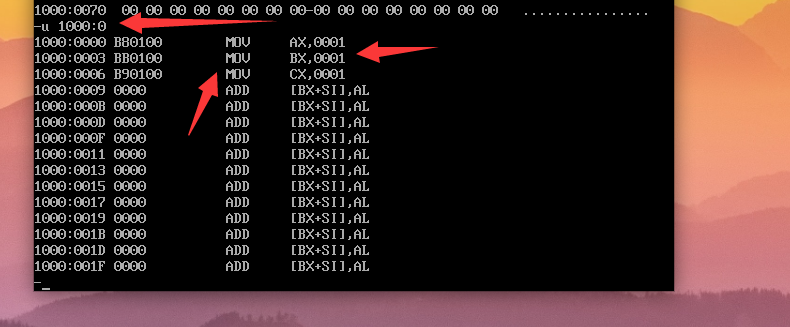
t命令,从cs:ip地址对应的内存单元开始执行机器指令;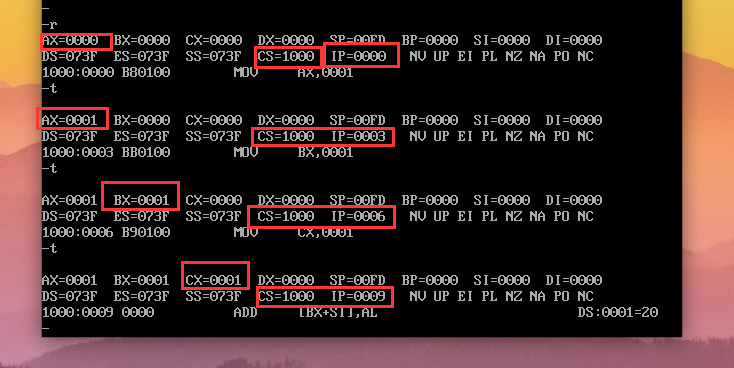
a 段地址(SA):偏移地址(EA)命令,可以从对应地址的内存单元开始写入汇编指令;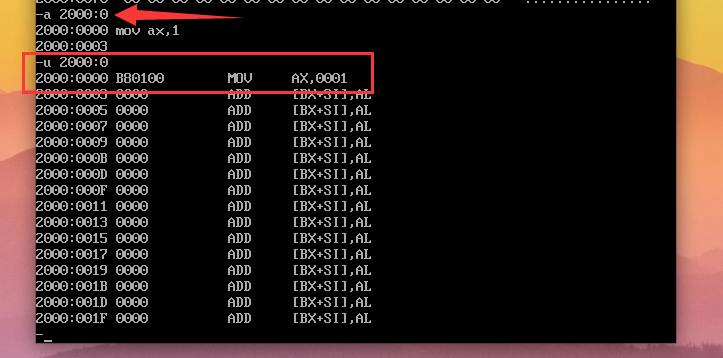
以上就是汇编debug调试器的简单使用方法,建议大家多练习。方便后面调试汇编程序使用。
必要的基础知识
汇编语言的种类
汇编语言可以按照不同的标准分为好几种。但是这里,我们只按照汇编格式分为两类:
- Intel汇编格式
- AT&T 汇编格式
这里我们用的是Intel,基于的CPU为8086,可以理解为Intel通常是在windows上使用,而AT&T则通常在GNU/Linux或者Unix中使用。
这里提一句,这两类汇编语言语法并不相同,所以要移植的话,需要去修改对应的语法。
机器语言、汇编语言、高级语言
机器语言: 即计算机直接理解的语言,这里语言其实就是二进制的数。
比如:8086CPU要完成运算s = 768+12288-1280,对应的机器码为101110000000000000000011000001010000000000110000001011010000000000000101
但是为什么我们在debug中见不到这种机器码呢?因为在debug中,这些二进制的机器码是以十六进制显示的。
汇编语言: 为了不让写代码变成输入0或者1的繁琐的事情,最早的程序员想到了用一些单词去代替繁琐的01。
比如有这样的很有对比性的实例,将寄存器bx中的内容传给寄存器ax中
汇编代码:mov ax,bx
十六进制码:89D8H
机器语言:1000100111011000
高级语言: 为了更加简化代码,引入更方便复杂的机制,程序员又写出了一些高级语言,这些语言有各种的撸码思想,比如函数式编程,面向对象编程,递归编程等。
而这三类语言,最普遍的关系就是:高级语言 –(编译)-> 汇编语言 –(编译、链接)-> 机器语言 –(CPU总线)-> 存储器(内存) –> CPU执行
汇编语言的组成
既然我们要学习汇编语言,就首先要知道这个编程语言的语法组成。
- 汇编指令:这类代码是有着对应的机器码的,具有实际的操作。
- 伪指令:没有对应的机器码,纯粹是为了方便程序员进行更方便的编程,计算机不会执行。
- 其他符号:比如-、+、*、/等,通常没有对应的机器码。
核心:汇编指令。
存储器和数据
CPU是一个计算机的逻辑推演的核心,但是如果这个核心没有记忆的输入,那么它也是无用的。比如人而言,如果人的大脑只会进行逻辑推理,运算,但是无法存储记忆(或者说记忆只有7秒),那么这个人的大脑也是无法进行运算量,逻辑复杂的运算和推理。
所以,一个计算机一定是要有存储器的,用来存储临时的数据的。最常见的存储器就是内存,内存和磁盘不同,内存可以直接被CPU访问和操作。如果CPU想要操作磁盘的数据时,也要把数据读入内存中才可以进行相关操作。
在内存中,CPU所写入的内容都是数据,这就是说,我们写入内存中的指令也是数据的一种。
比如我们在前面提到的,指令a SA:EA可以在对应地址的内存上写入指令,当写入完成后,我们用d SA:EA查看时,它就是一条数据。
存储单元 (重点)
存储器的基本单位是存储单元,一个存储单元有8个二进制位。
如图关系: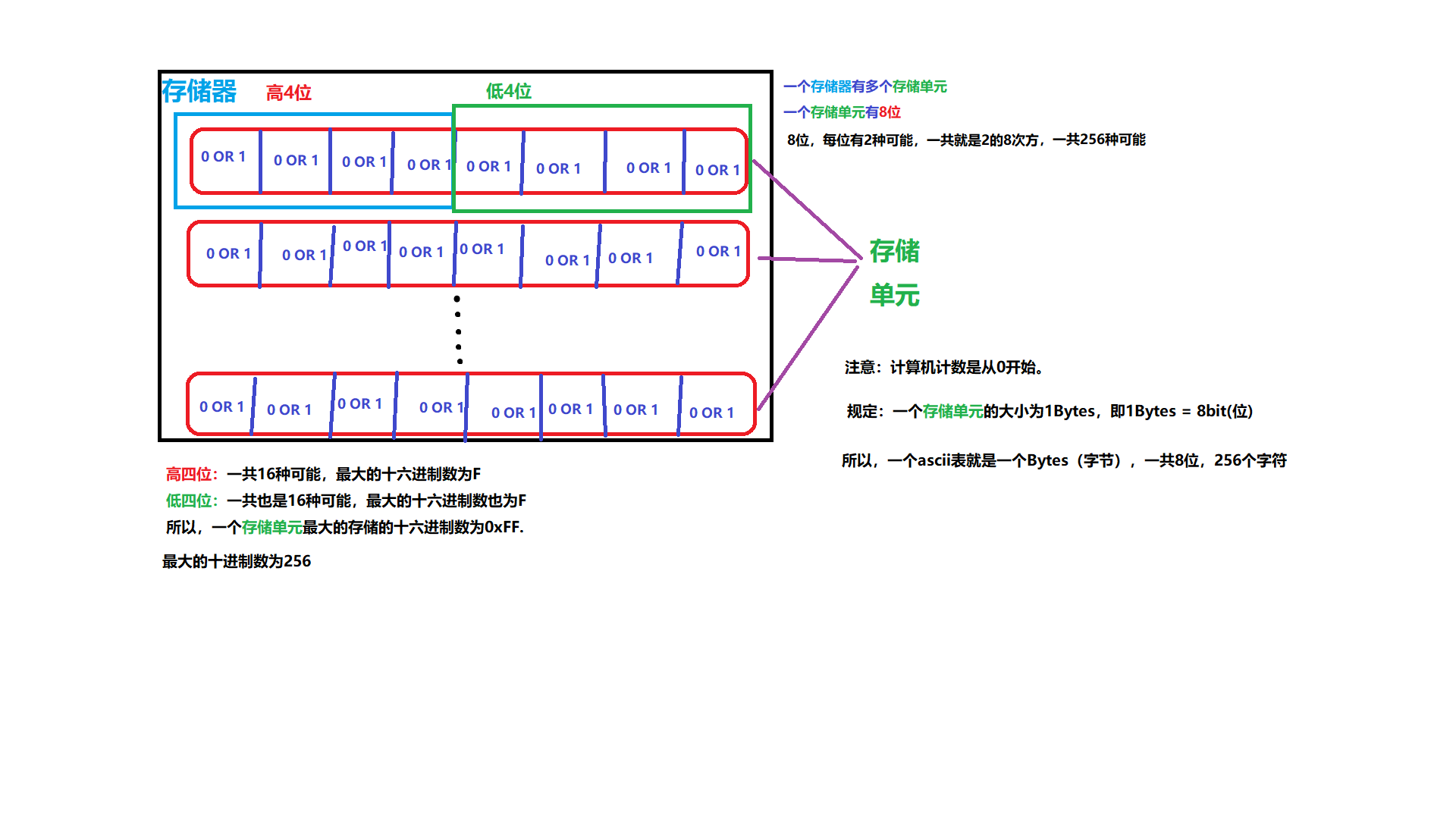
存储器信息容量单位转换:
1 Bytes = 8bit
1 Kb = 1024 Bytes
1 Mb = 1024 Kb
1 Gb = 1024 Mb
1 Tb = 1024 Gb
1 Pb = 1024 Tb
CPU的总线及CPU通过总线对存储器的读(read)和写(write)
把CPU想象成一个摆货员,存储器(内存)想象成一个大仓库,这个仓库有十分多的有着门牌的小隔间。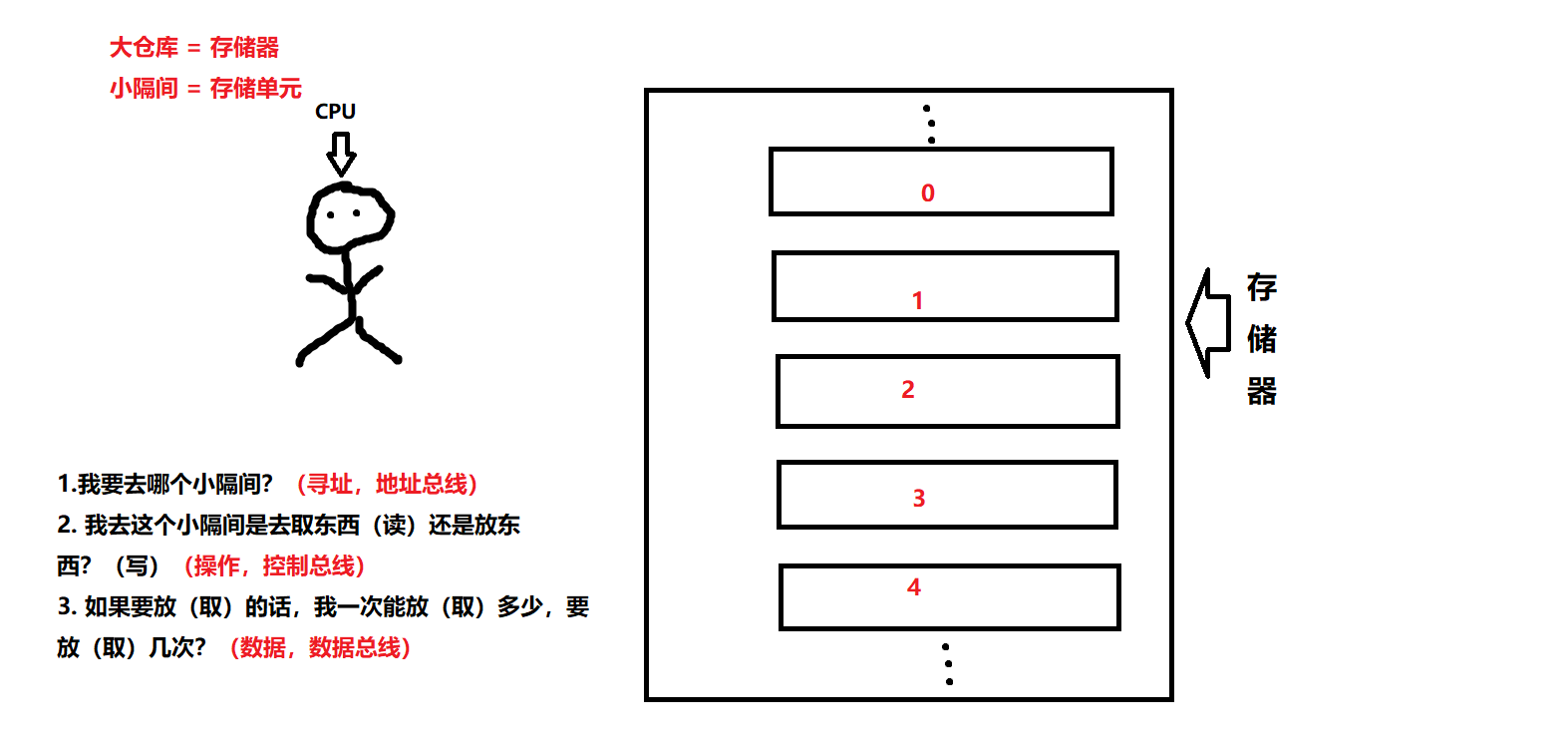
通过图片(哪位好心人投个好看的图)可以发现,如果CPU要对内存进行操作的话,我们需要知道:对存储器中的哪个存储单元进行操作?如何操作?
为了解决这个问题,CPU在设计的时候,就有了三种线路。
- 地址总线(用来找存储单元)
- 控制总线(对存储单元是进行读出还是写入)
- 数据总线(用来与存储单元进行数据的传输)
这三者总称为CPU总线,其实这三者在物理层面就用了一根导线。
现在,我们来说地址总线。
为什么这地址总线会有个总呢?这是因为地址总线是多个地址线的集合。对我们所用的8086CPU而言,它的地址总线有20个地址线。
每一个地址线都有两种可能,即有电没电(高电平,低电平,用二进制就是1,0)。
现在,一共有20个地址线,每个线有两种可能,那么一共就有2^20,即1,048,576种可能。
通常,CPU的地址总线有多少个地址线,我们就称CPU的地址总线宽度为多少。
现在,我们8086CPU的地址总线,就可以寻找2^20,即1,048,576个存储单元。
前面我们说过,一个存储单元的大小为1 Bytes,那么2^20个存储单元,就一共能存储2^20 Bytes。转化单位,就是1mb的大小。当地址总线越宽,那么这个CPU的寻址能力越强。
比如现在有4GB的内存(存储器),那么使用8086CPU就只能使用1mb大小的内存,这是很浪费的行为。所以当时CPU的设计者就提出了使用一种很聪明的方式,这种方式可以让CPU充分的利用内存(存储器)
说完了地址总线,我们就来说数据总线。
数据总线也是多个数据线的集合。每个数据线和地址总线一样,也只有0或1。
我们的8086CPU数据总线宽度为16。也就是说,CPU和存储器通信,一次只能传送16 bit的数据,而1 Bytes = 8bit,所以我们的8086CPU的数据传输,一次传输只能传输2 字节的数据。
当一个数据大小为4 字节的时候,CPU会自动分两个传输。
接下来是说控制总线。
CPU是计算机的核心,它连接着计算机所有的外部设备,所以它也是需要对这些设备进行控制的。而控制总线的作用就是控制这些设备,CPU的控制总线越宽,它能控制的设备就越多,控制能力越强。
而控制总线就两个控制选项:读出read 或者 写入write。
这里以后会有拓展知识,这方面知识在操作系统种会很常见。
就是关于CPU和外部设备的通信方式:轮询,中断,DMA传输。
内存地址空间
在数学上,通常一个空间,其本质就是一个集合里的所有点。
那么地址空间,就是一个集合里的所有地址。
当一个CPU的地址总线宽度为10的时候,其可以寻址的存储单元数量是2^10个,也就是1024个。
那么这个CPU地址总线能寻到的地址的最大数量,其每个地址组成的集合,就是内存地址空间。
主板、接口卡
每个PC机里,都会有一个主板,这个主板有最核心的CPU和一些主要器件。这些器件通过CPU的地址总线相连,每个主页也会有扩展槽,这些扩展槽也是和CPU相连。总之主板上的所有器件,都基本得和CPU连接。
每个外部设备,其实都有一个控制器,这个控制器再和CPU相连。这些控制器称为:接口卡。接口卡收到CPU的命令和数据,再去控制外部设备。
思路就是:CPU ——> 接口卡 ——> 外部器件
各类存储器和
- 随机存储器 RAM(内存条)
- ROM(装有各类BIOS)
- 接口卡的RAM(显卡)
它们都通过地址总线与CPU相连,使得CPU可以寻址到他们,进而控制他们。
当然,这里也有讲究。
CPU把这些外部设备的地址编入和内存地址相同的地址空间,这种方法称为:统一编址。
CPU把这些外部设备的地址编入一个特殊的地址空间种,这种方法称为:独立编址。
寄存器
上面我们说了CPU的总线,现在我们来说CPU的寄存器。
CPU通常是由以下结构组成:
- 运算器:进行信息处理
- 寄存器:对信息进行临时保存
- 控制器:控制各器件
- 高速缓存:存储内存种最常用或者特殊设置的地址
我们要讲的寄存器是CPU内部的临时的存储器,而且寄存器数量通常很多,因为作用不同。CPU内从寄存器之间是靠内部总线进行连接的。
通用寄存器
在我们所学的8086CPU中,所有寄存器都是16位的,可以存放两个字节(1B = 8Bit),一共有14个寄存器(CPU不同,数量不同,功能不同)。为AX,BX,CX,DX,BP,SI,DI,DS,IP,CS,ES,SS,SP,PSW.
其中,寄存器AX,BX,CX,DX通常用来存放一般性的数据,称为通用寄存器。
而这四个寄存器又可以按照位数分,分为高位(HIGH)和低位(LOW)。注意的是,这里的高位和低位不再是高4位和低4位,而是高8位和低8位,因为这四个寄存器本身就都是16位的。AX: AH 和 ALBX: BH 和 BLCX: CH 和 CLDX: DH 和 DL
现在,我们来取AX寄存器演示一下。
这里我们发现,每一个寄存器都有4个可输入的数字。
这里的4个数字和我们的16位是如何对应上的呢?
首先,debug的调试中,所有寄存器的数都是十六进制的,我们把16位的寄存器分为高低各8位。
那么,一个8位的显示最大的十六进制数位FF,两个8位,即可以显示的最大数字就是FFFF。所以,这里的AX寄存器是4个十六进制是数字。
新尺寸的单位的数据: “字”
之前我们聊的基本单位是:字节,Bytes
现在,我们介绍一个新的数据尺寸单位:字,Word字节和字的关系是:1字 = 2字节。
也就是说,1 字(Word)的大小是2 字节(Bytes),16位。在8086CPU中,一个寄存器刚好可以存放1 字。
在debug中修改寄存器的数据。
进入debug,输入r查看寄存器数据。
我们修改寄存器AX为0101: r ax,然后输入0101,再按Enter。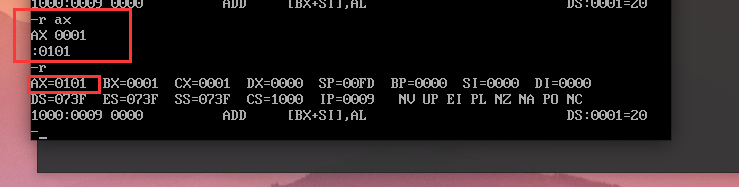
物理地址、寻址方式
前面我们介绍过地址总线,CPU对内存的操作首先要找到要操作的存储单元的地址。那么,通常的寻址方式是怎么样的呢?
我们把存储器(物理内存)看作是一个大的数组,数组中的每个元素就是存储单元,每个存储单元都有唯一的地址与之对应,这个地址称为物理地址。总线通过物理地址访问对应的存储单元。
如果程序直接把所有东西写在了固定的物理内存上,那么,问题就来了。
- 如果有两个程序的物理内存有重叠,那么就可能会导致程序的奔溃。
- 如果按照这种方法,那么一个地址总线宽度为16的CPU所能寻址的最大内存为
2^16即64Kb,如果此时内存是1mb,就会有非常多的内存浪费。
由此,便引入了一种相对的思想,这种想法很妙,这就是分段。
首先,诞生了一种这样的想法,就是内存访问的地址进行分段,给出段地址,然后在给出相对段地址的增量,这种增量称为偏移地址,这里的偏移是相对于段地址的那么最后的物理地址 = 段地址 + 偏移地址。
其次,为了解决第二个问题,后来CPU的设计人员将传入的段地址左移4位,或者说段地址*16,将得到的地址再去加上偏移地址,就得到了物理地址。物理地址 = 段地址*16 + 偏移地址。